NodeLocal DNSCache 启用
简介
NodeLocal DNSCache 通过在集群节点上作为 DaemonSet 运行 dns 缓存代理来提高集群 DNS 性能。在今天的架构中,ClusterFirst DNS 模式下的 Pod 会访问 kube-dns serviceIP 以进行 DNS 查询。这通过 kube-proxy 添加的 iptables 规则转换为 kube-dns/CoreDNS 端点。使用这种新架构,Pods 将接触到运行在同一节点上的 dns 缓存代理,从而避免 iptables DNAT 规则和连接跟踪。本地缓存代理将查询 kube-dns 服务以查找集群主机名(默认为 cluster.local 后缀)的缓存未命中。
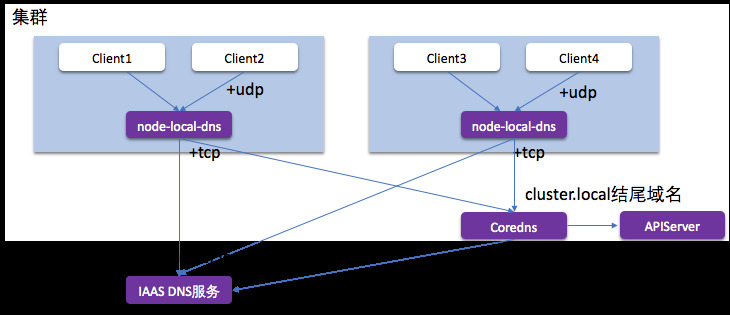
- 拦截 Pod 的 DNS 查询的请求
- 将外部域名分流,外部域名请求不再请求中心 Coredns
- 中间链路使用更稳定的 TCP 解析
- 节点级别缓存 DNS 解析结果,较少请求中信 Coredns
k8s拓扑感知服务路由
开启拓扑感知服务路由特性需同时启动ServiceTopology=true和EndpointSlice=true的FeatureGate
EndpointSlices简介
FEATURE STATE: Kubernetes v1.17 [beta]
EndpointSlices提供了一种简单的方法来跟踪Kubernetes集群中的网络Endpoints。 它们为Endpoints提供了更可扩展和可扩展的替代方案。 Endpoints API提供了一种简单而直接的方式来跟踪Kubernetes中的网络Endpoints。 不幸的是,随着Kubernetes集群和服务能够处理更多流量并将其发送到更多后端Pod,该原始API的局限性变得更加明显。 最值得注意的是,这些挑战包括扩展到更多网络Endpoints的挑战。 由于服务的所有网络Endpoints都存储在单个Endpoints资源中,因此这些资源可能会变得很大。 这影响了Kubernetes组件(尤其是主控制平面)的性能,并在Endpoints更改时导致大量网络流量和处理。 EndpointSlices可帮助您减轻这些问题,并为诸如拓扑路由之类的其他功能提供可扩展的平台。
Eni多IP方案调研
背景
Eni多IP方案是由 VPC 功能负责路由,打通容器网络的连通性,可实现 Pod 和 Node 的控制面和数据面完全在同一网络层面,该模式下的 Pod 能够复用VPC 所有产品特性。
VPC-CNI(多IP共享) 模式和VPC-CNI(独占)模式下,集群内 Pod 与 Node 的 IP 均来自同一 VPC。区别是,独占模式指的是pod独享一块弹性网卡,而多IP共享模式指的是多个pod共享一块弹性网卡,将弹性网卡的辅助ip分配给pod,通过这种方式,增加单个Node上可以创建的pod数量。
注:但由于弹性网卡辅助 IP 数量的限制,单个 Node 上可以创建的 Pod 数量仍然会受到限制,但综合pod数量和性能的考虑,目前该方案已属较优。
ENI多IP方案支持的最大Pod数=(云主机支持的ENI数-1)×单个ENI支持的私有IP个数
跳过CloudFlare 5秒盾和浏览器检查
被 Cloudflare 保护的站点,在初次访问时,会等待 5 秒钟的验证,检测你是不是通过浏览器正常访问的,如下图:
爬虫如何绕过 Cloudflare 的 DDos 保护验证
本文主要说明如果通过技术手段绕过这个验证,我试了两种办法,都管用。
Docker daemon 宕机期间保持容器存活
默认情况下,当 Docker daemon 退出的时候, 会关闭正在运行的容器。从 1.12 开始,可以配置 daemon 参数,使容器在 daemon 进程不可用的时候已经保持运行。改参数降低了在 daemon 崩溃、计划性维护以及升级时容器的停止时间。
vGPU隔离方案
主要两个思路:
- 将GPU纳入cgroup管理,目前尚未有成熟的提案,短期内难以实现(阿里云估计是基于cgroup实现的);
- 基于GPU驱动封装实现,用户根据需要对驱动的某些关键接口(如显存分配、cuda thread创建等)进行封装劫持,在劫持过程中限制用户进程对计算资源的使用。
此类方案缺点是兼容性依赖于厂商驱动,但是整体方案较为轻量化,性能损耗极小(腾讯云的gpu-manager采用了该方案,据了解浪潮也是采用的这个方案)。
下面,基于对gpu-manager的源码和论文进行研究,讲述“劫持”方案的实现原理。